How to Deadlock a Java ExecutorService
In this blog post I want to have a close look at a type of deadlock you can run into with any Java ExecutorService with a bounded number of threads. While rare in practice, the necessary ingredients to trigger it are always at your fingertips, especially around the shared ForkJoinPool#commonPool.
First, I’ll introduce you to the problem at an abstract level, in a lab setting. Then I will walk you through how I recently ran into this problem in the wild, while working on more-log4j2, and conclude with a few recommendations.
Minimal Reproduction
Let me explain the heart of the problem at an abstract level, before showing you how to reproduce it with a few lines of
code. What you need for a minimal reproduction is a single-threaded executor service executor and a task taskS that is
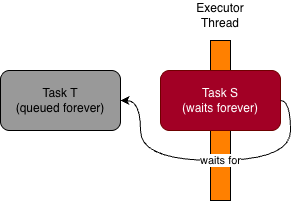
scheduled on executor. taskS schedules another taskT on executor, and waits for its completion synchronously. Since
executor has only one thread that is already occupied by taskS, taskT can never start, and taskS therefore waits forever.
You might find it helpful to have a look at the following diagram, which captures the scenario I’ve just described:
A minimal reproduction based on the aforementioned ideas has only a few lines of code:
void main() {
var executor = Executors.newSingleThreadExecutor(Thread.ofPlatform().daemon().factory());
Runnable taskT = () -> out.println("T done");
Runnable taskS = () -> {
CompletableFuture.runAsync(taskT, executor).join();
out.println("S done");
};
CompletableFuture.runAsync(taskS, executor).join();
}
Note that Executors.newSingleThreadExecutor(Thread.ofPlatform().daemon().factory()) is used in favor of
Executors.newSingleThreadExecutor() to make sure that executor threads cannot prevent the program from terminating. The only
potential reason for the program to hang is therefore the last line in main, which schedules and waits for taskS.
If you run this program, you can confirm that it indeed hangs, and all println statements are dead code.
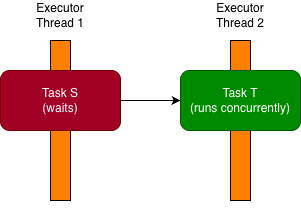
Before we move on, let’s look at two ways to fix the deadlock. Probably the most obvious way is to add a thread to the executor, as in
var executor = Executors.newFixedThreadPool(2, Thread.ofPlatform().daemon().factory());
Then taskT can execute while taskS waits for it as in the following picture:
However, the implementation is easily adapted to also deadlock with 2 threads:
void main() {
var executor = Executors.newFixedThreadPool(2, Thread.ofPlatform().daemon().factory());
IntFunction<Runnable> newTaskT = i -> () -> out.printf("T%s done%n", i);
IntFunction<Runnable> newTaskS = i -> () -> {
CompletableFuture.runAsync(newTaskT.apply(i), executor).join();
out.printf("S%s done%n", i);
};
CompletableFuture.allOf(
CompletableFuture.runAsync(newTaskS.apply(1), executor),
CompletableFuture.runAsync(newTaskS.apply(2), executor)
).join();
}
What happens if you execute the code above is captured in the diagram below:
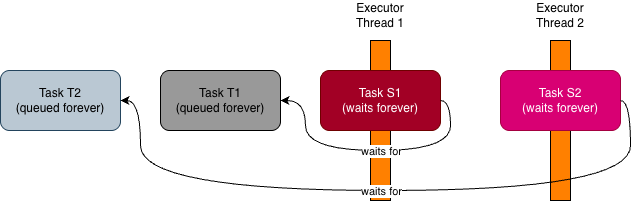
To reproduce the deadlock, both S1 and S2 have to start before either T1 or T2 gets a chance to run, and I hope it’s
clear from here how this generalizes to 3, 4, 5, … threads.
Luckily, there is another, more reliable way to get rid of the deadlock, without adding threads. The code can be unblocked by
letting taskS wait for taskT asynchronously, like in this snippet:
void main() {
var executor = Executors.newSingleThreadExecutor(Thread.ofPlatform().daemon().factory());
Runnable taskT = () -> out.println("T done");
Supplier<CompletableFuture<Void>> taskS = () ->
CompletableFuture.runAsync(taskT, executor).thenRun(() -> out.println("S done"));
CompletableFuture.supplyAsync(taskS, executor)
.thenCompose(f -> f) // Flattens Future<Future<...>> into Future<...>
.join();
}
This fixes the problem because taskS now releases its hold on the executor thread after scheduling taskT, and therefore allows
taskT to run. As you can confirm by instrumenting our executor with
var executor = new Executor() {
final Executor impl = Executors.newSingleThreadExecutor(Thread.ofPlatform().daemon().factory());
@Override
public void execute(Runnable command) {
out.printf("execute(%s)%n", command);
impl.execute(command);
}
};
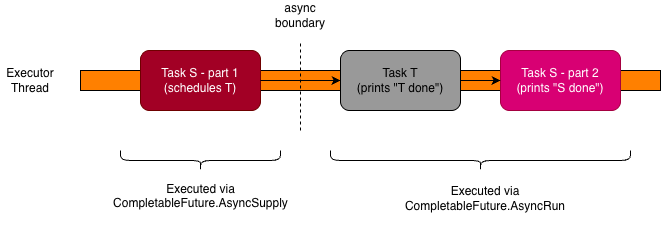
there are still two Runnables being submitted. The first one, implemented by CompletableFuture.AsyncSupply, corresponds to the
first part of taskS, which schedules taskT. The second one, implemented by CompletableFuture.AsyncRun, executes
taskT, and then the remaining part of taskS. Assembled in a diagram, you can picture what is going on as follows:
Implications and Impact in Practice
The examples I’ve presented so far are of course artificial. While interesting in theory, nobody and no-thing would ever write such code in practice, right?

Closely looking at the minimal reproduction again
void main() {
var executor = Executors.newSingleThreadExecutor(Thread.ofPlatform().daemon().factory());
Runnable taskT = () -> out.println("T done");
Runnable taskS = () -> {
CompletableFuture.runAsync(taskT, executor).join();
out.println("S done");
};
CompletableFuture.runAsync(taskS, executor).join();
}
we can observe at least the following:
- Many applications use single-threaded, or at least bounded executors.
- Many applications use a mixture of asynchronous and synchronous code.
- Many applications directly or indirectly submit tasks to executors from multiple places.
These points together, however, are exactly what is needed to run into a real-world version of the minimal reproduction above.
Unlike in our toy example, taskS and taskT could originate from different source files, modules or even libraries and the
affected executor could be managed by a framework.
Last but not least: This problem is not limited to CompletableFuture#join. A deadlock is possible whenever taskS running on a
bounded executor synchronously waits for a taskT on the same executor to do something. If the synchronous waiting is
implemented by CompletableFuture#join, CountDownLatch#await, Semaphore#acquire or BlockingQueue#put doesn’t matter in
this context.
Case Study of a Real-World Example
Let me add some depth to the discussion by having a closer look at how I ran into this issue recently in a realistic setting when working on more-log4j2. Feel free to jump directly to the visual summary at the end of this section if you like to skip the details.
Back at the end of April 2026, I was addressing bugs pointed out by Claude Sonnet 4.6. To make sure that I fixed them properly, I added a few tests that all passed locally. However, when I pushed these changes a few hours later, together with other commits, the CI builds started hanging and timing out after 6 hours.
It took me some time to figure out exactly what was happening. Luckily I did not follow some reasonable-sounding, but misleading explanations provided by Claude Opus 4.7 — I wanted to get to the bottom of it myself anyway.
Here is a brief summary: The problematic test AsyncHttpAppenderTest#shouldRespectMaxBatchBytesIncludingSeparatorsIfOverloaded
added
with 7acd211491b6ab46b78b4215a9a70d8d7d942eb4
instantiates a log4j2 configuration that contains an AsyncHttpAppender
that is configured to
- block practically indefinitely via
maxBlockOnOverflowMs=Integer.MAX_VALUEwhen it can’t keep up with the incoming logs - use an intentionally ridiculously small value for
maxBatchBytes.
This appender is then hammered via
var jobs = IntStream.range(0, 4)
.mapToObj(ignore -> CompletableFuture.runAsync(() -> {
for (int i = 0; i < 1000; i++) {
log.info("x");
}
})).toArray(CompletableFuture<?>[]::new);
assertThat(CompletableFuture.allOf(jobs)).succeedsWithin(1, TimeUnit.SECONDS);
As mentioned, this test passed without issues locally; however, it hung completely on the CI server. After some experimentation, I found out that I can reproduce the hanging on my laptop by setting
-Djava.util.concurrent.ForkJoinPool.common.parallelism=2
which restricts the number of threads in the ForkJoinPool#commonPool. Defaults that depend on the number of available CPU cores were the reason for the difference in behaviour.
To understand what happened and why, a closer look into the implementation of the AsyncHttpAppender is necessary. I’m trying to keep this as high level as possible, focusing only on the parts relevant for our discussion.
Relevant AsyncHttpAppender Mechanics
Let’s have a look at what happens in the appender when you call log.info(x):
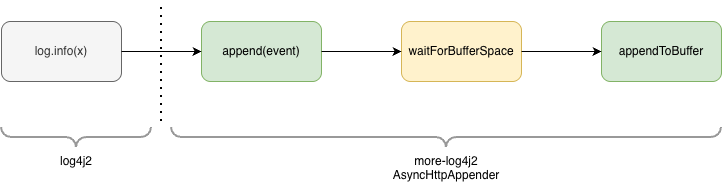
The most important thing about the drawing above is what it doesn’t contain: As you can see, the buffer is only appended to, but
not drained. Draining is done asynchronously by a single-threaded executor that is shared with the HttpAppender
implementation:

This drawing needs more explanation than the last one, so let’s go through it step by step:
- The
AsyncHttpAppenderlimits the number of concurrently executing HTTP requests to5by default. This is implemented by a semaphore, which needs to be acquired before invoking the HTTP client. However, the implementation does not callSemaphore#acquire(), because that can block. Blocking is something to do very cautiously in this context anyway, since the thread we are running on is shared with the HTTP client. In this case it would be fatal though: Since the semaphore is only released after the HTTP client returns, blocking the thread would guarantee that this never happens, and we would be deadlocked immediately. For that reason the implementation usesSemaphore#tryAcquire(), which never blocks. IftryAcquirefails, the appender reschedules a drain attempt on the executor using an exponential backoff logic, and releases the thread. This is what the diagram colloquially paraphrases as “async acquire”. - Batches that are ready to be sent are kept in a queue, which is polled here. Note that in the actual implementation, the semaphore is only acquired if there is something to poll.
- This is the step where
java.net.http.HttpClient#sendAsyncis invoked. - After
HttpClient#sendAsync()is done, the semaphore that we acquired previously needs to be released. Simplified, this is done likehttpClient.sendAsync(buildRequest(batch), HttpResponse.BodyHandlers.ofString()) .whenComplete((_, _) -> allowedInFlight.release());
At this point we have discussed everything you need to know about the AsyncHttpAppender implementation. To get the full
picture, we need to have a brief look at a surprising detail of the HttpClient implementation as well.
How and why java.net.http.HttpClient uses the common ForkJoinPool
I already mentioned that the AsyncHttpAppender shares an executor with the HttpClient it uses, which is passed into the client
at construction time via HttpClient.Builder#executor. Therefore, you might be tempted to assume that the HttpClient
implementation is not using the common ForkJoinPool at all. That’s at least what I thought — until the aforementioned
problem led my attention to HttpClientImpl#sendAsync. In there
you can find
// makes sure that any dependent actions happen in the CF default
// executor. This is only needed for sendAsync(...), when
// exchangeExecutor is non-null.
return res.isDone() ? res
: res.whenCompleteAsync((r, t) ->{ /* do nothing */}, ASYNC_POOL);
where res is a CompletableFuture<HttpResponse<T>> containing our response and ASYNC_POOL points to the common ForkJoinPool.
As hinted by the comment, the sole purpose of
res.whenCompleteAsync((r, t) -> { /* do nothing */}, ASYNC_POOL)
is to make sure that dependent, non-async completions are not
run on the executor of the HttpClient, but on the common ForkJoinPool. What are “dependent, non-async completions”? Well,
completions affecting the future returned by
CompletionStage#thenApply,CompletionStage#thenRun,CompletionStage#thenAccept,CompletionStage#thenCombineand so on
but not
CompletionStage#thenApplyAsync,CompletionStage#thenRunAsync,CompletionStage#thenAcceptAsync,CompletionStage#thenCombineAsyncand so on.
The lambdas you pass to any of these non-async methods are run
- either by the thread that completes the future these transformations are depending on
- or directly by the caller of
thenApply,thenRun, … if invoked on futures that are already completed.
Thus,
res.whenCompleteAsync((r, t) -> { /* do nothing */}, ASYNC_POOL)
ensures that the future returned to callers is completed by the common ForkJoinPool. This is a defensive measure against users
of the library who chain heavyweight operations to the returned future, which could starve the executor of the
HttpClient, and severely degrade its functionality.
In my opinion, it would be nice to give users a way to intervene, by allowing them to optionally configure a second executor
in addition to HttpClient.Builder#executor, which would then be used instead of ASYNC_POOL, but that’s another topic and
probably best addressed elsewhere.
Connecting the Dots
Finally, we have all we need to understand why the test hangs with
-Djava.util.concurrent.ForkJoinPool.common.parallelism=2
but runs fine with the default number of threads
Math.max(1, Runtime.getRuntime().availableProcessors() - 1)
on typical consumer hardware. What we are seeing is exactly the kind of executor deadlock I’ve explained in isolation in the first part of this blog post. The code below
var jobs = IntStream.range(0, 4)
.mapToObj(ignore -> CompletableFuture.runAsync(() -> {
for (int i = 0; i < 1000; i++) {
log.info("x");
}
})).toArray(CompletableFuture<?>[]::new);
deliberately overloads the appender, which is configured to block when it can’t keep up. As a result, both threads in the common
ForkJoinPool — used by CompletableFuture#runAsync when no executor is provided — end up being blocked. At the same time, the previously
discussed semaphore, which limits the number of concurrent HTTP requests, runs out of permits. These permits are never released,
because their release is chained after
res.whenCompleteAsync((r, t) -> { /* do nothing */}, ASYNC_POOL)
which is not executed, since all threads in the common pool are blocked. You can picture it like this:
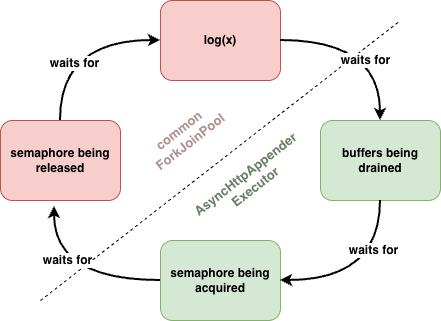 The common ForkJoinPool is busy with logging, which blocks because buffers are full; buffers can’t be drained, because that
requires a semaphore permit; the semaphore is not released, because the common ForkJoinPool is busy with logging.
The common ForkJoinPool is busy with logging, which blocks because buffers are full; buffers can’t be drained, because that
requires a semaphore permit; the semaphore is not released, because the common ForkJoinPool is busy with logging.
If the number of threads in the common ForkJoinPool is greater than 4 — the number of concurrent logging jobs — the test passes
without issues, since then there are threads that can pick up the work chained after the completion of the HTTP request, and
release the semaphore.
To fix the tests, I therefore adapted them to run potentially blocking tasks in another, test-specific executor.
Final Remarks and Recommendations
I hope that this discussion gave you a sense of the problem, both in its abstract form and how it might play out in realistic code. Though it’s hard to come up with a simple guideline that will reliably prevent it, here are two recommendations that should at least help:
- The common
ForkJoinPoolis a shared resource, which might be used in unexpected ways. Make sure you don’t overload it, and use a dedicated executor if in doubt. - If you run into this problem, adding threads might be a viable quick fix. Don’t stop there, though — address the real issue: synchronously waiting for something that can only be completed by a task in the same bounded executor.
The best remedy, though, is a profound understanding of the problem, since that will help you with preventing, debugging and properly addressing this issue.