JMH for LLMs
The Idea
I recently had a conversation about Java casting performance with Microsoft Copilot, mostly to test the model, but also open to learning something new. Very soon, Copilot suggested to generate a JMH benchmark for me, and being curious, I agreed. What followed sparked my interest, because it became clear pretty quickly, that I had overstretched the capabilities of the model. This inspired the following idea: While JMH benchmarks are typically used to measure runtimes of Java code snippets, why not use them differently, by comparing the ability of LLMs to create JMH benchmarks to answer subtle performance related questions?
The Game
Thus, I decided to run a competition between different models, which me being the referee. The conversation with each model would start with the following prompt:
I know that casts in Java are pretty cheap, since JVM implementations go at great lengths to make them as performant as possible. However, even cheap operations add up when executed in large enough numbers. Because Java collections are operating on plain
Objectreferences, with implicit casts being inserted by the compiler as needed, typical Java programs contain far more casts than meets the eye.To make this more concrete, I’m wondering how much casting overhead is involved when iterating over an
ArrayList<Integer>. Is it always negligible, or can it have a significant impact in tight loops?Please don’t answer my questions directly. Instead, I would like you to generate a JMH benchmark class to shed some light on this topic. The benchmark should be small and finish in less than a minute. Adding some comments to the source code to help interpret the results would be a bonus, but please be concise. Also, please restrict your answer to the JMH benchmark class only; I don’t need instructions on how to run it. I’ll execute the benchmark and share the results so we can analyze them together.
I would then run the benchmark, and respond with
Thanks. Here are the results of the benchmark:
${JMH results table}
Would you like to refine the benchmark? If you think that the numbers look reasonable, and the benchmark should remain as is, please reply with “no”. Otherwise, please provide an updated JMH benchmark class.
After that I would end the conversation, and discuss potential problems in the generated benchmarks, concluding with a score out
of {0, 1, 2} with
0meaning useless, or even misleading1meaning OK, though there is room for improvement2meaning good.
This score will be mostly affected by the second attempt of the model, if there is one, since this iterative approach also most closely resembles how humans write benchmarks. I could of course give the models multiple chances to refine their benchmarks, but I decided to stop after one iteration, to keep the scope limited.
The Participants
The next problem was choosing the participants. Due to resource constraints, I wanted to limit myself to 4 models, thus it’s very likely that your favorite LLM is not in the list. It should however be straight forward enough to replicate what I did for any model, at least if you don’t wait for too long, because it’s only a matter of time till models will learn about this article in one way or another. Here are the participating LLMs:
- Microsoft Copilot using
Smart (GPT-5)mode - Microsoft Copilot using
Think Deepermode - Google Gemini 2.5 Pro
- deepseek V3 using
DeepThinkmode
All of them are accessible without paid subscriptions.
The Competition
The following sections describe and discuss the interactions I had with the participating models on the 29th of August 2025, one by one. Each of them will be concluded with a score as outlined above. The full interaction protocol can be found here.
Microsoft Copilot Smart (GPT-5)
Here is the benchmark proposed by Copilot in Smart (GPT-5) mode:
/**
* Benchmark to measure potential overhead of casting when iterating over ArrayList<Integer>.
*
* - baseline(): uses primitive int[] (no boxing/unboxing, no casting)
* - implicitCast(): iterates over ArrayList<Integer> with implicit casts from Object
* - explicitCast(): same as implicitCast but with an explicit (Integer) cast
*
* If implicitCast and explicitCast are slower than baseline, the difference may be due to
* casting, boxing/unboxing, or both. The gap between implicitCast and explicitCast isolates
* the cost of the explicit cast itself.
*/
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
public class CastOverheadBenchmark {
private static final int SIZE = 1_000;
private List<Integer> list;
private int[] array;
@Setup
public void setup() {
list = new ArrayList<>(SIZE);
array = new int[SIZE];
for (int i = 0; i < SIZE; i++) {
list.add(i);
array[i] = i;
}
}
@Benchmark
public int baseline() {
int sum = 0;
for (int v : array) {
sum += v;
}
return sum;
}
@Benchmark
public int implicitCast() {
int sum = 0;
for (Integer v : list) { // implicit cast from Object to Integer
sum += v;
}
return sum;
}
@Benchmark
public int explicitCast() {
int sum = 0;
for (Object o : list) {
sum += (Integer) o; // explicit cast
}
return sum;
}
}
After the benchmark class, Copilot concluded, amongst other remarks, with
This should complete well under a minute with default JMH settings.
In reality, one of the first things that caught my attention after starting the benchmark was ETA 00:25:00 being written to the
console. Since I didn’t want to wait, I added
@Fork(1)
@Warmup(iterations = 3, time = 100, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 200, timeUnit = TimeUnit.MILLISECONDS)
and soon had results like
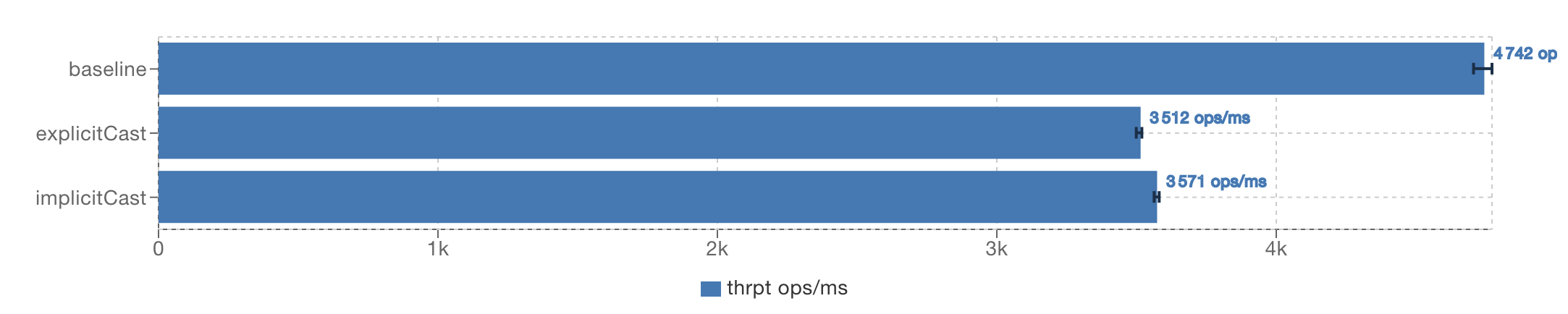
Since Copilot didn’t want to refine the benchmark after the second prompt, let me discuss the code, and what these numbers actually tell us.
As you can see, explicitCast and implicitCast have more or less the same execution speeds. Everything else would be very
surprising, since both methods, at the bytecode level, iterate over a list of objects, that are then cast and summed up as
integers. Weather the casts appear explicitly in the source code, or are added implicitly by the compiler, doesn’t matter to the
CPU executing the instructions. It also doesn’t matter to anybody wanting to learn about the performance implications of casting.
The fact that basline, which operates on int[] outperforms the other two methods by a significant margin, doesn’t tell us very
much about casting either, since there are too many factors that contribute to the difference:
- Fewer indirections & better memory locality for
int[]. - Fewer indirections, because the array is accessed directly, and not via a
Listobject. - No casting.
Therefore, I’m concluding with a score of 0.
Microsoft Copilot (Think Deeper)
Copilot in “Think Deeper” mode did somewhat better:
- The generated benchmark had an acceptable ETA from the start.
- The useless performance comparison between “explicit” and “implicit” casts was removed.
What remained, was a comparison between summing over int[] and ArrayList<Integer>, that we already discussed above:
/**
* Pure primitive loop: no casts or object indirection.
*/
@Benchmark
public long sumArray(Data data) {
long sum = 0;
int[] a = data.array;
for (int i = 0; i < a.length; i++) {
sum += a[i];
}
return sum;
}
/**
* Boxed loop: each get() does a CHECKCAST to Integer, then auto-unboxes.
*/
@Benchmark
public long sumList(Data data) {
long sum = 0;
List<Integer> l = data.list;
for (int i = 0, n = l.size(); i < n; i++) {
sum += l.get(i);
}
return sum;
}
Since the model stayed with this benchmark, even after having given the chance to refine it, my score is 0 once again.
Google Gemini 2.5 Pro
Gemini 2.5 is the only model that made use of it’s second chance. While the first submission just compared summing up int[]
with a sum over an ArrayList<Integer>, very much like the benchmark we just discussed, the refined version the model generated
looks different:
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
@Fork(value = 1, warmups = 1)
@Warmup(iterations = 5, time = 1)
@Measurement(iterations = 5, time = 1)
public class CastingBenchmark {
@Param({"1000"})
private int size;
private ArrayList<Integer> arrayList;
private Integer[] integerArray;
private Object[] objectArray;
private int[] primitiveArray;
@Setup
public void setup() {
Random random = new Random(1234);
arrayList = new ArrayList<>(size);
integerArray = new Integer[size];
objectArray = new Object[size];
primitiveArray = new int[size];
for (int i = 0; i < size; i++) {
int value = random.nextInt();
Integer integerValue = value; // Box once
arrayList.add(integerValue);
integerArray[i] = integerValue;
objectArray[i] = integerValue;
primitiveArray[i] = value;
}
}
/**
* Baseline: Iterates over a primitive int array.
* No objects, no casting, no unboxing. This is the theoretical best-case scenario.
*/
@Benchmark
public int sumPrimitiveArray() {
int sum = 0;
for (int i : primitiveArray) {
sum += i;
}
return sum;
}
/**
* Iterates over an Integer[] array.
* This involves object access and unboxing for each element, but no type casting,
* as the array's type is already known to be Integer[].
*/
@Benchmark
public int sumIntegerArray() {
int sum = 0;
for (Integer i : integerArray) {
sum += i;
}
return sum;
}
/**
* Iterates over an Object[] array known to contain Integers.
* This requires an explicit (or in a for-each loop, implicit) cast and then unboxing.
* This is very similar to ArrayList's internal behavior but without the get() method call overhead.
*/
@Benchmark
public int sumObjectArrayWithCast() {
int sum = 0;
for (Object o : objectArray) {
sum += (Integer) o;
}
return sum;
}
/**
* The original test: iterates over an ArrayList<Integer>.
* This involves the list's get() method call, a type cast, and unboxing.
* This measures the performance of a typical generic collection loop.
*/
@Benchmark
public int sumArrayList() {
int sum = 0;
for (Integer i : arrayList) {
sum += i;
}
return sum;
}
}
Summarizing, this benchmark compares summing over int[], Integer[], Object[] and List<Integer>. It took around 2 minutes
to execute on my laptop, which is somewhat longer then the minute asked for in the prompt, but still tolerable, even for somebody
as impatient as me. If you arrange the results from fastest to slowest, like below
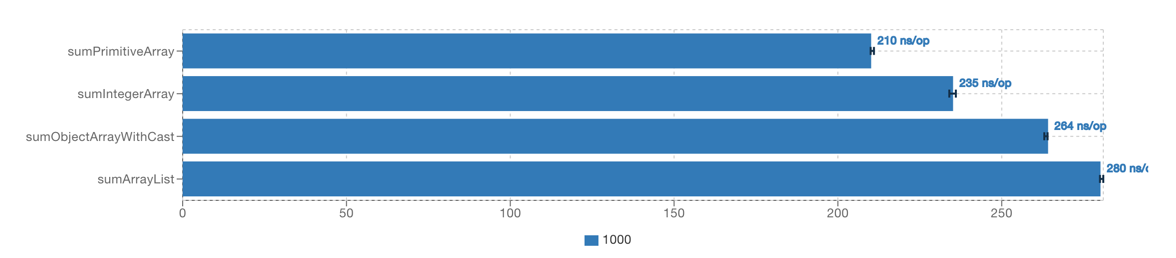 you can see, how starting from the performance of
you can see, how starting from the performance of int[], we finally end up at the performance of ArrayList<Integer>, in steps.
In the first step, we transition from int to Integer, and add a boxing overhead. Then we go from Integer[] to Object[]
and add a casting overhead. And finally we add one more indirection, and move from Object[] to ArrayList<Integer>. Concluding,
we can say that if all you do is summing up numbers, the casting overhead involved when iterating over an
ArrayList<Integer> is somewhere in the range of 10%. Though, as we shall later see, much more can be said about this topic, I
would consider this benchmark a reasonable first attempt in the right direction, and give Gemini a score of 1.
deepseek V3
The benchmark generated by deepsek V3 is similar to the one generated by Gemini, though incomplete: It compares summation of
Integer[] with summation of an ArrayList<Integer> and looks like:
@State(Scope.Thread)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 3, time = 500, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 5, time = 500, timeUnit = TimeUnit.MILLISECONDS)
public class ArrayListCastBenchmark {
private ArrayList<Integer> arrayList;
private Integer[] array;
@Setup
public void setup() {
int size = 10000;
arrayList = new ArrayList<>(size);
array = new Integer[size];
for (int i = 0; i < size; i++) {
arrayList.add(i);
array[i] = i;
}
}
// Baseline: Iterate over pre-cast Integer array (no casts in loop)
@Benchmark
public long baselineArray() {
long sum = 0;
for (Integer integer : array) {
sum += integer;
}
return sum;
}
// Tests ArrayList iteration with implicit casts in get()
@Benchmark
public long arrayListGet() {
long sum = 0;
for (int i = 0; i < arrayList.size(); i++) {
sum += arrayList.get(i); // Includes cast from Object to Integer
}
return sum;
}
// Tests ArrayList iteration with iterator (implicit casts in next())
@Benchmark
public long arrayListForEach() {
long sum = 0;
for (Integer integer : arrayList) { // Includes cast in iterator.next()
sum += integer;
}
return sum;
}
}
The model decided to stay with this benchmark, after having received the results. As we saw while discussing the submission by
Gemini, going from Integer[] to ArrayList<Integer> not only adds a casting overhead, but potentially also an indirection
overhead. Since this benchmark doesn’t explicitly check Object[], it’s hard to tell which parts of the performance degradation
that can be observed when moving from Integer[] to ArrayList<Integer> should be attributed to casting. Therefore, I’m
concluding with a score of 0, though it’s a close call.
Summary & Winner
The clear winner of this contest is Google Gemini 2.5 Pro, since it’s the only model, that provided a benchmark that actually
can be used to derive some information about the casting overhead that one pays while iterating over an ArrayList<Integer>. The
benchmarks provided by Microsoft Copilot compared int[] with ArrayList<Integer> which is interesting as well, but wasn’t
what the prompt asked for. deepseek V3 would have won if only one response was allowed, but was then outperformed by Gemini,
which used the opportunity to refine it’s relatively weak first attempt.
Regardless of their score, each of these models is an extremely impressive piece of technology.
My Benchmark to answer the Prompt
Before wrapping things up, let me give you my take on an answer to the aforementioned prompt. Note that I spent hours digging though benchmark results, profiler output and generated assembler code, before wrapping up my results, and presenting them to you. Here is the benchmark class that I finally came up with after lots of tinkering:
/**
* This benchmark demonstrates how casting overhead can impact loops iterating over lists.
*
* <p>
* All benchmark methods are prefixed with `groupX`. Always look at results from one group at a time.
* Comparing results from different groups doesn't make sense if you are interested in the overhead
* incurred by implicit casts. Here is a brief summary of the different groups:
*
* <ul>
* <li>group0 compares reading a reference to reading and an implicit cast, while iterating</li>
* <li>group1 compares copying a reference to copying and an implicit cast, while iterating</li>
* <li>group2 compares calling hashCode to calling hashCode and an implicit cast, while iterating</li>
* <li>group3 does the same as group2, but iterates over <code>Object[]</code> and <code>Integer[]</code></li>
* </ul>
* </p>
*/
@Fork(1)
@Warmup(iterations = 3, time = 100, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 200, timeUnit = TimeUnit.MILLISECONDS)
@BenchmarkMode(Mode.Throughput)
@State(Scope.Thread)
public class ListCastingOverheadBenchmark {
@Param("100000")
private int length;
private ArrayList<Integer> integerArrayList;
private ArrayList<Object> objectArrayList;
private ArraySink arraySink;
private Object[] objectArray;
private Integer[] integerArray;
@Setup
public void setup() {
integerArrayList = new ArrayList<>(length);
objectArrayList = new ArrayList<>(length);
arraySink = new ArraySink(length);
objectArray = new Object[length];
integerArray = new Integer[length];
var rng = new Random(123);
for (int i = 0; i < length; i++) {
integerArrayList.add(rng.nextInt());
objectArrayList.add(integerArrayList.getLast());
objectArray[i] = integerArrayList.getLast();
integerArray[i] = integerArrayList.getLast();
}
}
@Benchmark
public void group0ConsumeObjectArrayList(Blackhole bh) {
for (Object o : objectArrayList) {
bh.consume(o);
}
}
@Benchmark
public void group0ConsumeIntegerArrayList(Blackhole bh) {
for (Integer i : integerArrayList) {
bh.consume(i);
}
}
@Benchmark
public ArraySink group1CopyReferencesIntegerArrayList() {
arraySink.reset();
for (Integer i : integerArrayList) {
arraySink.consumeInteger(i);
}
return arraySink;
}
@Benchmark
public ArraySink group1CopyReferencesObjectArrayList() {
arraySink.reset();
for (Object o : objectArrayList) {
arraySink.consumeObject(o);
}
return arraySink;
}
@Benchmark
public void group2ConsumeIntegerArrayListHashCodes(Blackhole bh) {
for (Integer i : integerArrayList) {
bh.consume(i.hashCode());
}
}
@Benchmark
public void group2ConsumeObjectArrayListHashCodes(Blackhole bh) {
for (Object o : objectArrayList) {
bh.consume(o.hashCode());
}
}
@Benchmark
public void group3ConsumeIntegerArrayHashCodes(Blackhole bh) {
for (Integer i : integerArray) {
bh.consume(i.hashCode());
}
}
@Benchmark
public void group3ConsumeObjectArrayHashCodes(Blackhole bh) {
for (Object o : objectArray) {
bh.consume(o.hashCode());
}
}
/**
* A custom sink, that stores objects in an internal array.
*
* @implNote objects are written in reverse order to prevent smart compilers from figuring out that they could
* just use {@link System#arraycopy(Object, int, Object, int, int)} instead of consuming objects one by one under
* specific conditions.
*/
public static final class ArraySink {
final Object[] values;
int pos;
ArraySink(int size) {
this.values = new Object[size];
this.pos = values.length - 1;
}
void consumeObject(Object o) {
values[pos--] = o;
}
void consumeInteger(Integer i) {
values[pos--] = i;
}
void reset() {
pos = values.length - 1;
}
}
}
This is quite some code, with benchmarks being split into groups. Let’s discuss them one by one:
Group 0: Casting in Isolation
For your convenience, let me paste the benchmark methods from group 0 here again:
@Benchmark
public void group0ConsumeObjectArrayList(Blackhole bh) {
for (Object o : objectArrayList) {
bh.consume(o);
}
}
@Benchmark
public void group0ConsumeIntegerArrayList(Blackhole bh) {
for (Integer i : integerArrayList) {
bh.consume(i);
}
}
Both methods iterate over an array list containing exactly the same elements, however the first one consumes them as plain
objects, and the second one as Integer objects. If you look into the Java bytecode corresponding to these two methods, you can
confirm that they are identical, except for a single CHECKCAST java/lang/Integer instruction, that appears only in
group0ConsumeIntegerArrayList but not in group0ConsumeObjectArrayList. Since nothing else is happening in the loop, comparing
the results of these two benchmarks shows us how much casting costs compared to iteration and the costs implied by the Blackhole
implementation. Here is a plot generated by the courtesy of Microsoft Copilot with the results from my laptop using
OpenJDK 64-Bit Server VM, 24.0.2:
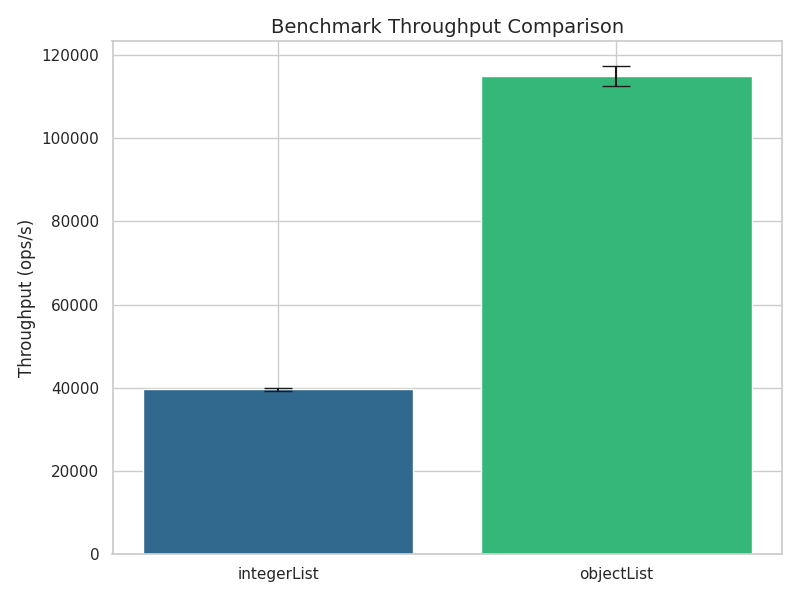
As you can see, in this highly artificial scenario, casting is not for free at all, but adds a significant overhead. Digging
though the ARM assembly, I found that CHECKCAST java/lang/Integer is being compiled to something like
ldr w12, [x4, #8] // loads the class pointer at offset 8, from the object addressed by x4 into register w12
mov x11, #0x190000 // these two movs store the address of java/lang/Integer into register x11
movk x11, #0x1ee0
cmp w12, w11 // compares the class of the object with java/lang/Integer
b.ne 0x0000000116e67724 // jumps to an uncommon call trap if the cast fails
Thus, it’s not that surprising, that these 5 instructions can add overhead, if we are doing nothing else in the loop body. Now, does it mean that typical Java programms are doomed to eternal slowness, due to implicit casts from the standard collectins library and other generic classes? Let’s have a look at the benchmarks from
Group 1: Copying References & Casting
@Benchmark
public ArraySink group1CopyReferencesIntegerArrayList() {
arraySink.reset();
for (Integer i : integerArrayList) {
arraySink.consumeInteger(i);
}
return arraySink;
}
@Benchmark
public ArraySink group1CopyReferencesObjectArrayList() {
arraySink.reset();
for (Object o : objectArrayList) {
arraySink.consumeObject(o);
}
return arraySink;
}
/**
* A custom sink, that stores objects in an internal array.
*
* @implNote objects are written in reverse order to prevent smart compilers from figuring out that they could
* use an equivalent of {@link System#arraycopy(Object, int, Object, int, int)} under certain conditions.
*/
public static final class ArraySink {
final Object[] values;
int pos;
ArraySink(int size) {
this.values = new Object[size];
this.pos = values.length - 1;
}
void consumeObject(Object o) {
values[pos--] = o;
}
void consumeInteger(Integer i) {
values[pos--] = i;
}
void reset() {
pos = values.length - 1;
}
}
Again, both group1CopyReferencesIntegerArrayList and group1CopyReferencesObjectArrayList iterate over an array list, and copy
the object references one by one over to another Object array. The first method contains an implicit cast, the second one
doesn’t. Note that the loop body is still very short, and involves just copying references, and decrementing a counter. However,
looking at the benchmark results, the picture looks very different:
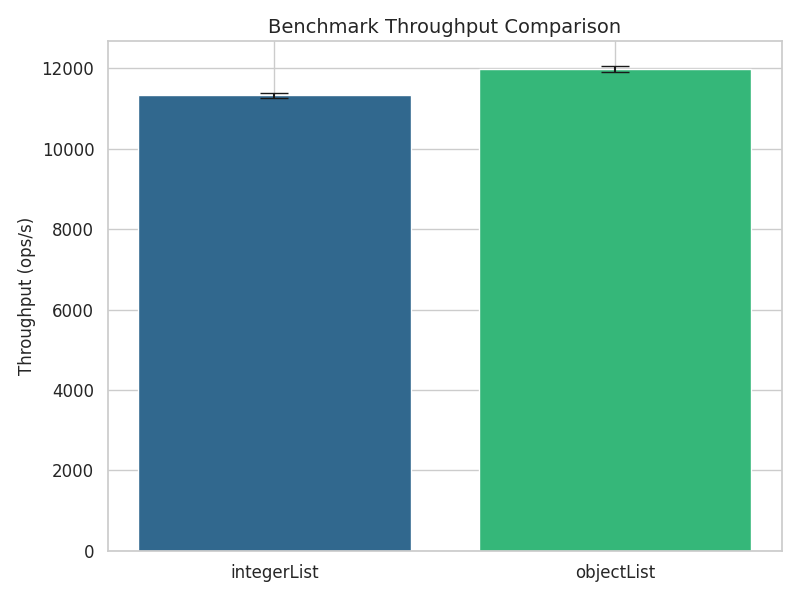
While previously, the version without the cast was almost 3 times faster, now we are taking about an overhead of roughly 5%. Note
that the loops in group 1 are still somewhat atypical, because the object based version of the loop, that is measured by
group1CopyReferencesObjectArrayList is able to get away by only manipulating object references, whereas the implicit cast in
group1CopyReferencesIntegerArrayList forces the runtime to access the referenced objects themselves. Let’s move on to
Group 2: Invoking Methods & Casting
In this group of benchmarks, Object#hashCode is invoked in the loop body:
@Benchmark
public void group2ConsumeIntegerArrayListHashCodes(Blackhole bh) {
for (Integer i : integerArrayList) {
bh.consume(i.hashCode());
}
}
@Benchmark
public void group2ConsumeObjectArrayListHashCodes(Blackhole bh) {
for (Object o : objectArrayList) {
bh.consume(o.hashCode());
}
}
Here are the results:
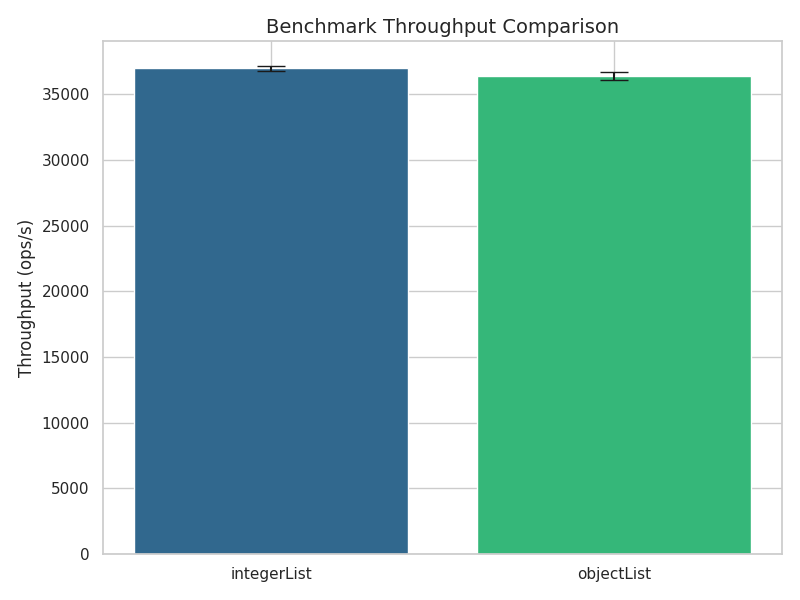
This time, there is no significant difference between the two versions. To avoid a virtual function call and enable inlining, JIT
inserts a check for Integer even into the Object based version of the loop, which explains why both methods have essentially
the same running time.
Can we therefore conclude that casting overhead doesn’t matter if the involved objects are accessed even in the most trivial way? Let’s have a look at the final
Group 3: Iterating Over Arrays directly
What if we had a reified ArrayList that used Integer[] instead of Object[] as internal storage? Would that in some cases
outperform a regular ArrayList<Integer>? In order to find out, we could of course copy and paste the source code of ArrayList
and adapt it’s backing array and all related parts of the code accordingly, and then benchmark this tweaked IntegerArrayList
against its vanilla counterpart. However, whatever performance benefit or penalty this would bring, it would always boil down to
the difference between Object[] and Integer[], so I decided to cut a few corners, and just replicated the benchmark from group
2, but this time with Integer[] and Object[]:
@Benchmark
public void group3ConsumeIntegerArrayHashCodes(Blackhole bh) {
for (Integer i : integerArray) {
bh.consume(i.hashCode());
}
}
@Benchmark
public void group3ConsumeObjectArrayHashCodes(Blackhole bh) {
for (Object o : objectArray) {
bh.consume(o.hashCode());
}
}
Here are the numbers:
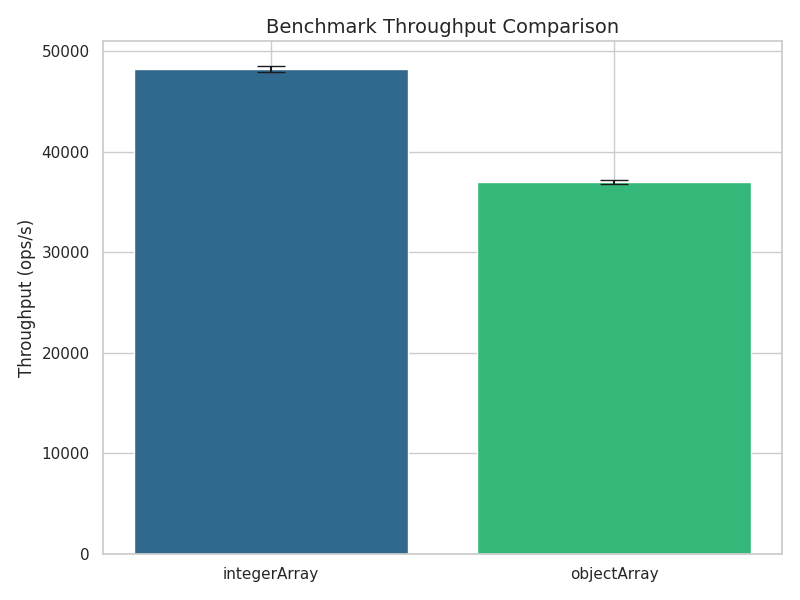
As you can see, the Integer[] array based version wins by roughly 30%. The reason for this difference in runtimes is already
hinted at by differences in the Java byte code. In group3ConsumeIntegerArrayHashCodes the hash code is calculated by
INVOKEVIRTUAL java/lang/Integer.hashCode ()I. Since Integer is a final class, this call can be inlined without additional type
checks. group3ConsumeObjectArrayHashCodes though contains
INVOKEVIRTUAL java/lang/Object.hashCode ()I, and the inlining cannot proceed without inserting type checks that make sure that
we are actually dealing with Integer instances.
Are Casts now Cheap or What?
Unfortunately, the answer is both yes and no. While typically negligible, implicit casts implied by Java collection usage can add significant overhead, if loop bodies are short, and reified types would allow for inlining without additional runtime type checks.
Wrapping Up
The capabilities of modern LLMs are impressive, and they can be a very useful tool for a variety of situations, especially when their output can be easily validated, or errors are cheap. If any of these conditions is not met, they are far less useful though, at least unless there is another break-though.
In the context of benchmarking, LLMs have helped me quite a bit when digging through JIT generated assembly, or for plot generation1. Designing and writing micro-benchmarks though is definitely not something that I’d leave to an LLM. Even if I got the perfect JMH benchmark, the actual work is anyway validating and understanding its implications.
Footnotes
-
Normally I use jmh-visualizer. ↩