What the Hell is GetOpaque in Java
In this blog post, that can be seen as a follow-up of my last post about acquire release semantics, I want to shine some light on getOpaque and setOpaque.
I’ll show how it is defined and what that means in practice, as well as how get and setOpaque relate
to the weaker getPlain and setPlain and the stronger getAcquire and setRelease.
Javadocs and their Interpretation
Unfortunately, the Javadocs
of get and setOpaque are somewhat vague, stating
public final Object getOpaque(Object… args)
Returns the value of a variable, accessed in program order, but with no assurance of memory ordering effects with respect to other threads.
public final void setOpaque(Object… args)
Sets the value of a variable to the newValue, in program order, but with no assurance of memory ordering effects with respect to other threads.
Rephrasing this, it means that the runtime or hardware must not reorder opaque operations with other opaque operations on the same variable. It is, however, perfectly legal to reorder opaque operations with other opaque operations on different variables.
To illustrate what that means, I’ve put together a small JCStress test here:
@JCStressTest
@Description("Demonstrates the behaviour of opaque mode")
@Outcome(id = "0, 0, 0", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 0, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 0, 2", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 1, 0", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 1, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "0, 1, 2", expect = Expect.ACCEPTABLE)
@Outcome(id = "1, 0, 0", expect = Expect.FORBIDDEN, desc = "b=1, then b=0")
@Outcome(id = "1, 0, 1", expect = Expect.ACCEPTABLE_INTERESTING, desc = "b=1, then a=0")
@Outcome(id = "1, 0, 2", expect = Expect.ACCEPTABLE_INTERESTING, desc = "b=1, then a=0")
@Outcome(id = "1, 1, 0", expect = Expect.FORBIDDEN, desc = "b=1, then b=0")
@Outcome(id = "1, 1, 1", expect = Expect.ACCEPTABLE)
@Outcome(id = "1, 1, 2", expect = Expect.ACCEPTABLE)
@Outcome(id = "2, 0, 0", expect = Expect.FORBIDDEN, desc = "b=2, then b=0")
@Outcome(id = "2, 0, 1", expect = Expect.FORBIDDEN, desc = "b=2, then b=1")
@Outcome(id = "2, 0, 2", expect = Expect.ACCEPTABLE_INTERESTING, desc = "b=2, then a=0")
@Outcome(id = "2, 1, 0", expect = Expect.FORBIDDEN, desc = "b=2, then b=0")
@Outcome(id = "2, 1, 1", expect = Expect.FORBIDDEN, desc = "b=2, then b=1")
@Outcome(id = "2, 1, 2", expect = Expect.ACCEPTABLE)
@State
public class AtomicIntegerSetGetOpaqueTest {
final AtomicInteger a = new AtomicInteger();
final AtomicInteger b = new AtomicInteger();
@Actor
public void actor1() {
a.setOpaque(1);
b.setOpaque(1);
b.setOpaque(2);
}
@Actor
public void actor2(III_Result r) {
r.r1 = b.getOpaque();
r.r2 = a.getOpaque();
r.r3 = b.getOpaque();
}
}
The test contains two atomics, a and b, and two actors, that execute concurrently. Note that actor 1 writes a first,
but actor 2 reads b first. The list of @Outcome annotations attached to the test class enumerates all imaginable 3 * 2 * 3 = 18
outcomes, and qualifies them as acceptable, interesting or forbidden. To execute this test after checking out this branch,
you need to run
$ mvn package -pl tests-custom -am -DskipTests
$ java -jar tests-custom/target/jcstress.jar -v -t AtomicIntegerSetGetOpaqueTest
Executing this on a Google Axion ARM VM, I get
Results across all configurations:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
0, 0, 0 467,556,008 48.46% Acceptable
0, 0, 1 54,242 <0.01% Acceptable
0, 0, 2 710,132 0.07% Acceptable
0, 1, 0 801,328 0.08% Acceptable
0, 1, 1 181,784 0.02% Acceptable
0, 1, 2 2,070,255 0.21% Acceptable
1, 0, 0 0 0.00% Forbidden b=1, then b=0
1, 0, 1 3,270 <0.01% Interesting b=1, then a=0
1, 0, 2 12 <0.01% Interesting b=1, then a=0
1, 1, 0 0 0.00% Forbidden b=1, then b=0
1, 1, 1 149,163 0.02% Acceptable
1, 1, 2 346,645 0.04% Acceptable
2, 0, 0 0 0.00% Forbidden b=2, then b=0
2, 0, 1 0 0.00% Forbidden b=2, then b=1
2, 0, 2 339,578 0.04% Interesting b=2, then a=0
2, 1, 0 0 0.00% Forbidden b=2, then b=0
2, 1, 1 0 0.00% Forbidden b=2, then b=1
2, 1, 2 492,645,876 51.06% Acceptable
Note the “interesting” results, where the writes to b are observed before the writes to a, though a is updated
before b in the Java code. This is legal, since opaque mode gives “no assurance of memory ordering effects with respect to
other threads”. To rule out the “interesting” cases, you can either switch to the more strongly ordered X86 architecture
(see Chapter 10.2 in Volume 3 in the Combined Volume Set of Intel® 64 and IA-32 Architectures Software Developer’s Manuals for details),
or upgrade to acquire-release mode (see my last blog post), like
this:
@Actor
public void actor1() {
a.setRelease(1);
b.setRelease(1);
b.setRelease(2);
}
@Actor
public void actor2(III_Result r) {
r.r1 = b.getAcquire();
r.r2 = a.getAcquire();
r.r3 = b.getAcquire();
}
Additional Documentation
Unfortunately, I could not find any additional official documentation apart from the Javadocs about getOpaque and
setOpaque. There is however a very well written, and comprehensive guide about
JDK 9 Memory Order Modes written by Doug Lea
who is the official author of most classes in java.util.concurrent, that contains a paragraph on
“opaque mode”. According to this document opaque mode is usable in the same contexts as
C++ atomic memory_order_relaxed, which is identical to
relaxed ordering in Rust. Opaque mode is also mentioned and explained in a very interesting
workshop by Aleksey Shipilev about Java Concurrency Stress (JCStress).
Use Cases for get and setOpaque
Opaque mode can be used whenever you want to share an update to a single value with other threads. This includes
primitive types, like boolean, int, long as well as references to immutable objects.
Publishing references to mutable objects using get and setOpaque however is unsafe, since reading
a reference with getOpaque that has been published with setOpaque does not establish a happens-before-relationship
with writes to non-final fields before the publication. Let me emphasize this essential point with
another JCStress test:
@JCStressTest
@Description("Shows why opaque mode must not used to publish objects with non final fields")
@Outcome(id = "42", expect = Expect.ACCEPTABLE)
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "observed partially constructed object")
@State
public class AtomicReferenceSetGetOpaqueTest {
static class Holder {
int x = 42;
}
final AtomicReference<Holder> ref = new AtomicReference<>();
@Actor
public void actor1() {
ref.setOpaque(new Holder());
}
@Actor
public void actor2(I_Result r) {
while (true) {
Holder h = ref.getOpaque();
if (h == null) {
Thread.onSpinWait();
continue;
}
r.r1 = h.x;
return;
}
}
}
Here one actor publishes a reference to a Holder object, that contains a non-final int, that is initialized to 42 in the
constructor. The other actor waits till the reference shows up, and then reads the int. Executing this on the same Google Axion ARM VM
I was mentioning before via
$ mvn package -pl tests-custom -am -DskipTests
$ java -jar tests-custom/target/jcstress.jar -v -t AtomicReferenceSetGetOpaqueTest
gives me
Results across all configurations:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
0 51,636 <0.01% Interesting observed partially constructed object
42 1,081,532,417 100.00% Acceptable
As you can see, even in this basic example, there is a tiny probability of things going south when using opaque mode to publish object references. Getting rid of the “interesting” outcome requires any of
- sticking to X86
- upgrading to at least acquire-release mode
- or making
xfinal.
Having said all that, let’s let’s come back to valid use cases.
Broadcasting a Stop Signal
Let’s assume that you have one or more worker threads running code like
while (!stopSignalRecieved()) {
doSomeWork();
}
and one thread that at some point should stop the workers. Then opaque mode is an option, like in
final AtomicBoolean stop = new AtomicBoolean();
void startWorkerLoop() {
while (!stop.getOpaque()) {
doSomeWork();
}
out.println("Stopped");
}
void sendStopSignal() {
stop.setOpaque(true);
}
Does it buy you something over just using volatile boolean, or AtomicBoolean.get and AtomicBoolean.set?
Probably not. On X86, reads are compiled to a single mov instruction, regardless of their type. On ARM,
plain and opaque reads are compiled to ldr instructions, whereas acquire and volatile reads are implemented using
ldar instructions. I assembled this JMH benchmark,
to gain a better understanding of the performance impact implied by different access modes, that calculates Fibonacci numbers while checking a stop flag.
The benchmark relies on the memory ordering enum
I’ve introduced in my last blog post and looks like
private final AtomicBoolean stop = new AtomicBoolean();
@Param({"VOLATILE", "ACQUIRE_RELEASE", "OPAQUE"})
private MemoryOrdering memoryOrdering;
@Param({"1", "10"})
private int batchSize;
@Param("100000")
private int limit;
@Benchmark
public int fibTillStop() {
final var mod = 1_000_000_007;
var fib0 = 0;
var fib1 = 1;
for (int i = 0; !memoryOrdering.get(stop) && i < limit; i += batchSize) {
for (int j = 0; j < batchSize; j++) {
var fib2 = fib0 + fib1;
if (fib2 >= mod) fib2 -= mod;
fib0 = fib1;
fib1 = fib2;
}
}
return fib1;
}
Executing this on a Google Axion ARM c4a-highcpu-4 instance with a corretto-24.0.1 JVM, I get
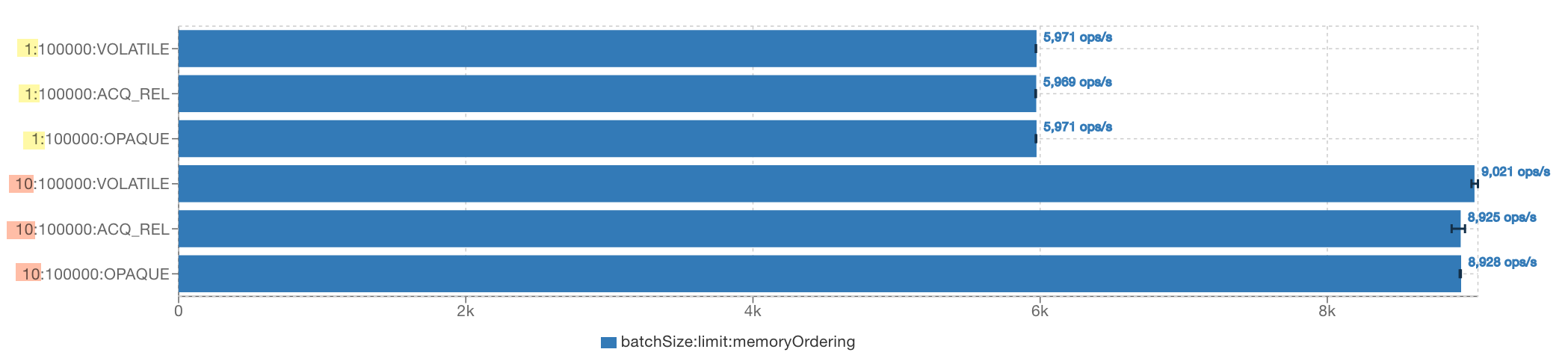 A similar picture can be observed on X86. Therefore, if you want to improve the performance
of a loop like the one above, using bigger batches, and not tweaking the memory ordering, is the way to go.
A similar picture can be observed on X86. Therefore, if you want to improve the performance
of a loop like the one above, using bigger batches, and not tweaking the memory ordering, is the way to go.
If you read the last paragraphs carefully, you might wonder why we couldn’t use plain reads and writes, that is plain mode, at least on X86 and ARM, to broadcast a stop signal. After all, the CPU instructions used for opaque access on ARM and X86 are ordinary loads. However, CPU instructions only matter if they are executed, which might not be the case in plain mode, since JIT will optimize the check for the stop flag away if it can prove that the loop body never modifies it. This proof typically succeeds if the loop body can be fully inlined. Let me illustrate this point by two examples:
static long brokenBroadcast() throws InterruptedException {
var stop = new AtomicBoolean();
var job = CompletableFuture.supplyAsync(() -> {
var spins = 0L;
while (!stop.getPlain()) {
spins++;
}
return spins;
});
Thread.sleep(100);
stop.setPlain(true);
return job.join();
}
public static void main() throws InterruptedException {
var spins = brokenBroadcast();
out.printf("Done after %s spins%n", spins);
}
This program will almost certainly never terminate, because the check for the stop flag will be optimized away by the JIT compiler. This variation however probably will:
static long brokenButAccidentallyWorkingBroadcast() throws InterruptedException {
var stop = new AtomicBoolean();
var job = CompletableFuture.supplyAsync(() -> {
var spins = 0L;
while (!stop.getPlain()) {
if (++spins % 1_000_000_000 == 0) {
out.printf("%s spins already...%n", spins);
}
}
return spins;
});
Thread.sleep(100);
stop.setPlain(true);
return job.join();
}
public static void main() throws InterruptedException {
var spins = brokenButAccidentallyWorkingBroadcast();
out.printf("Done after %s spins%n", spins);
}
For me this reliably prints
1000000000 spins already...
Done after 1000000000 spins
Am I always that lucky to terminate after exactly 1000000000 spins? Not quite, if you look into the generated assembler code (how to do this would be worth a blog post of its own; for the time being please have a look at the Developers disassemble! Use Java and hsdis to see it all blog post and check out the -XX:CompileCommand=print option) you’ll see that luck isn’t involved at all, since what is actually executed is:
long run() {
if (stop.getPlain()) {
return goBackToInterpreter();
}
var spins = 0;
do {
spins++;
pollForSafePoint(); // <-- https://shipilev.net/jvm/anatomy-quarks/22-safepoint-polls/
} while (spins % 1_000_000_000 != 0);
return goBackToInterpreter();
}
Let’s summarize the important parts:
- The generated code does not check the
stopflag in the loop at all. - As soon as it hits the if block with the
printf, it goes back to the interpreter.
The interpreter then invokes printf, and then continues execution by checking the stop flag, which at this point is
already true. Thus, the loop terminates after exactly 1_000_000_000 iterations.
So isn’t JIT going a bit over the top when simply removing the check for the stop flag? Maybe in this very particular case,
however, normally, this kind of optimization is exactly what you want, and far more
common than you might initially think. Let me give you an example: Every time you iterate over an
ArrayList, using for (var elem : arrayList), you theoretically have to pay for
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
again and again. This would incur a significant performance penalty for tight loops if JIT wasn’t allowed to optimize this check away as long as it can prove that the loop body doesn’t modify the list. The Java Memory Model has been specifically designed to allow these kinds of optimizations. The only reliable way to make sure that updates to a variable from one thread are eventually picked up by other threads without additional synchronization, is to use opaque, or a stronger memory ordering mode for both reads and writes.
Broadcasting Progress
Another legitimate use case for opaque mode is publishing progress information in a scenario where one thread performs some long-running task, and another thread monitors its progress. Simplified to its bare minimum, it could look like this:
final AtomicInteger progress = new AtomicInteger(0);
void workerThread() {
while (!done()) {
work();
progress.setOpaque(progress.getPlain() + 1);
}
}
void monitoringThread() throws InterruptedException {
while (!done()) {
out.printf("progress=%s%n", progress.getOpaque());
Thread.sleep(10);
}
}
When using plain writes, that is progress.setPlain(progress.getPlain() + 1) JIT might be tempted to “optimize”
workerThread() into
void workerThread() {
var progressInRegister = 0;
while (!done()) {
work();
progressInRegister++;
}
progress.setPlain(progressInRegister);
}
which is probably not what you indented. Opaque mode, as well as any stronger mode, prevents this optimization.
Summary & Recommendation
Opaque mode can be used to share a single value between threads, but it is poorly documented, and it comes with
absolutely no guarantees for other memory locations, which makes it too weak for many use cases. Even where it’s safe,
sticking with volatile is probably the better choice.